Blog
The Next Phase in Enterprise AI: System-Level Intelligence with vLLM Semantic Router
As enterprises move from experimental AI deployments to large-scale production, a stark reality has emerged: inference—specifically, simply throwing larger models at every problem—is becoming unsustainably expensive. The industry is rapidly shifting its focus from raw model scale to per-token efficiency and task-aware compute allocation.

Enter the vLLM Semantic Router, an intelligent routing layer designed for Mixture-of-Models (MoM) environments. Acting as the “System-Level Intelligence” for your infrastructure, it sits between your users and your language models to dynamically capture missing context, secure your endpoints, and radically optimize how compute is allocated
Here is a deep dive into what the vLLM Semantic Router is, why your enterprise needs it, how it works, and how to implement it
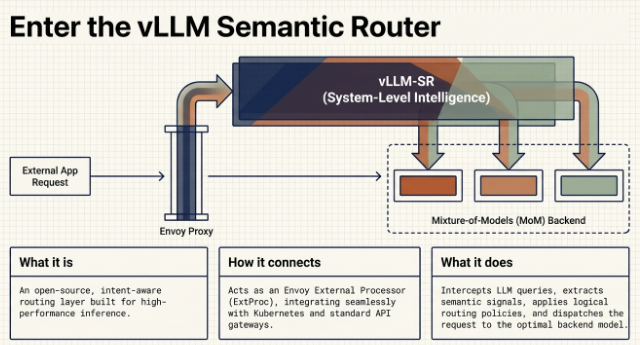
The Enterprise Dilemma: Why Intelligent Routing is Required
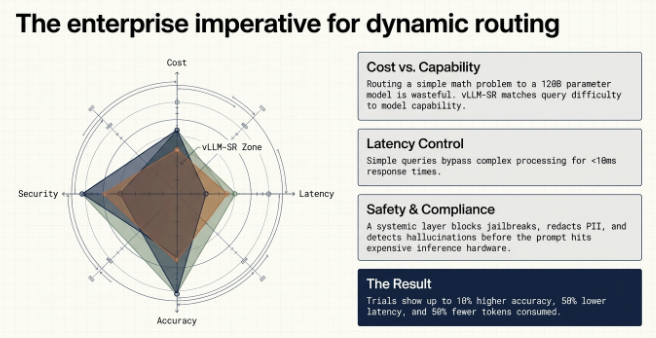
Today, developers face the “inference dilemma”: if you enable complex reasoning pathways for every query, your compute costs skyrocket; if you disable reasoning entirely, your accuracy on complex tasks plummets.
The vLLM Semantic Router solves this by introducing task-aware compute allocation. By inspecting the semantic intent of an incoming request, the router intelligently directs traffic to the most appropriate model.
- Simple queries (e.g., “What is the capital of France?”) are sent to lightweight, fast, and cheap models.
- Complex tasks (e.g., legal analysis or multi-step coding problems) are routed to expensive, Chain-of-Thought reasoning models.
The Cost Savings: For the enterprise, this translates directly to the bottom line. Trials have shown that by routing queries dynamically, organizations can achieve ~10% higher accuracy on complex tasks while using ~50% fewer tokens and experiencing ~50% lower latency. By reserving your high-value GPU compute solely for the tasks that actually need it, you drastically bring down your overall inference costs.
Architecture: Blocks, Interconnects, and Flows
The vLLM Semantic Router functions as an Envoy External Processor (ExtProc), processing standard HTTP requests before they ever reach your backend models.
The architecture is built upon four primary layers
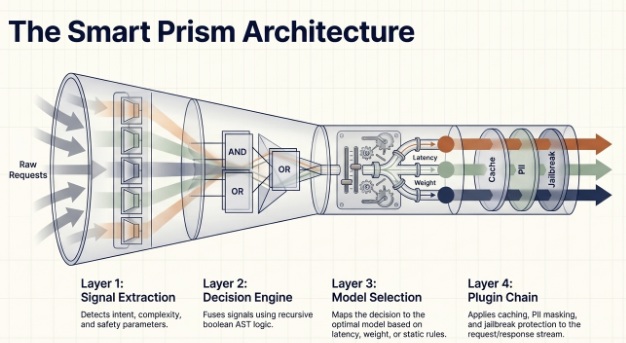
The architecture relies on four main layers. First, the Signal Extraction Layer captures up to 9 different request signals, such as the language being used, the token count context, or MMLU domain classification. Next, the Decision Engine fuses these signals using standard boolean logic. The Model Selection layer then picks the exact model, and finally, a Plugin Chain can mutate headers, detect hallucinations, or check semantic caches before the request even hits the backend
Let’s dive deep into each layer
The first critical component is the Signal Extraction Layer. This layer is designed to capture a rich set of up to nine request signals from the incoming prompt. These signals include technical metadata like the token count and context length, as well as semantic classification like the MMLU domain or the language used. By leveraging lightweight BERT models running on the CPU, this layer operates with extreme efficiency, ensuring that the full context of the user’s intent is identified before any compute is spent on the LLMs.
Once the Signal Extraction Layer has captured all the relevant request signals—such as the user’s intent, the MMLU domain, or the token count—the request moves to the Decision Engine. This is Layer 2 of the architecture. Its purpose is to fuse all those signals using standard boolean logic, essentially making the critical, rule-based decision: which model is the most appropriate and cost-efficient for this specific task? This step ensures that trivial prompts go to a fast, inexpensive model, while complex, high-value tasks are correctly routed to the powerful reasoning paths.”
Following the decision from the Decision Engine, the Model Selection layer takes the instruction and picks the exact model endpoint. This ensures that the determined model, whether a fast, small model for a simple query or a powerful reasoning model for a complex task, is correctly engaged.
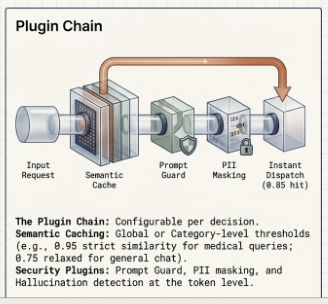
The final layer before the request hits the backend is the Plugin Chain.
This is a powerful, flexible layer where critical actions are taken. Plugins can perform tasks like mutating request headers for specific endpoints, running final checks for hallucination detection, or querying a semantic cache to reduce latency significantly before the request even reaches an LLM.
How It Works: Examples
To understand the flow, let’s look at how the router handles real-world enterprise scenarios using the configuration logic:
Example 1a: The Math & Reasoning Flow If a user submits a complex equation, the Signal Extraction Layer flags math-specific keywords (e.g., “derive”, “integral”) and detects a “hard” math complexity signal. The Decision Engine evaluates these signals and triggers a “Math” routing rule. The Model Selection Layer then routes the request to a heavyweight reasoning model (like DeepSeek or a massive GPT model) with use_reasoning: true enabled.
Example 1b: The General “Fast Path” Flow (No Reasoning Required) If a user submits a straightforward query or simple arithmetic (e.g., “What is the capital of France?” or “add two numbers”), the Signal Extraction Layer detects an “easy” complexity signal or classifies it under the “other” general domain. The Decision Engine evaluates these signals and triggers the “general queries” routing rule. Because deep analysis isn’t needed, the Model Selection Layer routes the request to a fast, lightweight base model (such as phi4) and explicitly sets use_reasoning: false. This immediately serves the response over a fast path, completely avoiding the latency and high token costs associated with a Chain-of-Thought reasoning model
Example 2: The Security & Caching Flow If a user asks a frequently asked question, but accidentally includes a Social Security Number, the Plugin Chain springs into action. First, a PII classification model detects the sensitive data and can mask or block it based on policy. Next, the semantic cache plugin recognizes that a semantically similar query was asked five minutes ago. It immediately serves the cached response, completely bypassing the backend LLM—resulting in zero GPU compute cost for that turn
Implementation and Setup
Deploying the router is highly efficient and designed for cloud-native enterprise environments (like Kubernetes).
Implementation Steps:
- CPU-Only Infrastructure: The router itself utilizes lightweight MoM (Mixture of Models) architectures, meaning the router runs entirely on the CPU (using Python 3.10+ and Docker/Podman) and requires zero GPU allocation.
- Configuration File: The entire system is governed by a single
config.yamlfile where you define your backend endpoints, your signals, and your routing rules. - Backend Mapping (Crucial Step): You must define your vLLM backend endpoints using valid IPv4 or IPv6 addresses. The most critical prerequisite is ensuring that the model names in your
config.yamlexactly match the--served-model-nameparameter you used when booting up your backend vLLM servers
Supported Backends and the LLM-D Synergy
The Semantic Router communicates using standard HTTP schemas, making it fully compatible with OpenAI-like API structures. While optimized for vLLM backends, it can sit in front of various inference runtimes, provided they accept standard payloads.
The Perfect Pair: vLLM-SR + LLM-D When designing massive scale-out enterprise infrastructure, it’s vital to understand how the vLLM Semantic Router (vLLM-SR) complements Distributed Inference platforms like LLM-D.
- vLLM-SR is a Model Picker: It semantically analyzes a query to decide which entirely different base model (e.g., a coding specialist vs. a general chat model) should handle the task.
- LLM-D is an Endpoint Picker: Once vLLM-SR selects the model, LLM-D takes over to decide which specific physical GPU endpoint (out of a distributed pool serving that exact model) should execute the inference.
Together, they provide the ultimate enterprise stack: intelligent, intent-based routing paired with massive, distributed scale-out performance
Enterprise Conclusion: A Strategic Imperative
As AI scales, the conversation has moved from “Can we run this model?” to “How can we run this model efficiently?”.
The vLLM Semantic Router offers enterprises a comprehensive, out-of-the-box solution to the inference dilemma. By fusing up to 9 different request signals, it acts as the brain of your API gateway—enforcing strict security compliance (blocking jailbreaks and masking PII in real-time) before a prompt ever touches your data.
Most importantly, the financial impact cannot be overstated. By enforcing task-aware compute allocation—leveraging semantic caching for trivial queries and dynamically reserving heavy reasoning models only for high-value tasks—enterprises can drastically slash their overall inference costs, reduce token consumption by half, and massively improve system latency.
The vLLM Semantic Router isn’t just a technical upgrade; it is the definitive strategy for running sustainable, secure, and cost-effective AI in the enterprise.
vLLM Semantic Router is a research-driven project focused on frontier problems in LLMRouting and Token economy. Get more infromation here vLLM Semantic Router
curl -fsSL https://vllm-semantic-router.com/install.sh | bash-----------------------------------------------------------------------------------------------------------More about the community Inferenceops.io team initiative: This team hosted the event on 14th March 2026 at Pune, India (part of vllm community driven event) and I along with Suresh had a talk on vllm semantic router. Keep an eye on future events where we talk all about InferenceOps. Join our community here.
————————————————————————————————————————————————————-
Author
Ritesh Shah
Ritesh Shah is a Senior Principal Architect with the Red Hat Portfolio Product Marketing and Learning team and focuses on creating and using next-generation platforms, including artificial intelligence/machine learning (AI/ML) workloads, application modernization and deployment, Disaster Recovery and…
Feedback
Share feedback on this post.
Add a correction, ask a question, or share what worked in your own production environment.